Representative End User Clients


Representative Automation Clients
Representative Software Clients


In The Industrial AI (R)Evolution we cut through the Generative AI hype, dispel myths, and summarize the decades old capabilities and latest developments and trends in the broader field of Industrial AI use cases.
ARC Advisory Group has identified 25 high value applications of Industrial AI. These use cases are a great starting point for industrial organizations to leverage the diverse AI tools and technologies available, including the innovative advancements in Generative AI. The aim is to ensure these tools can be effectively applied across the complete life cycle of sustainable products. From the preliminary stages of product and supply chain design, through the implementation phase of manufacturing and supply chain execution, to customer sales, service, and ensuring safe end-of-life disposal and recycling, these AI applications promise to deliver significant business value.
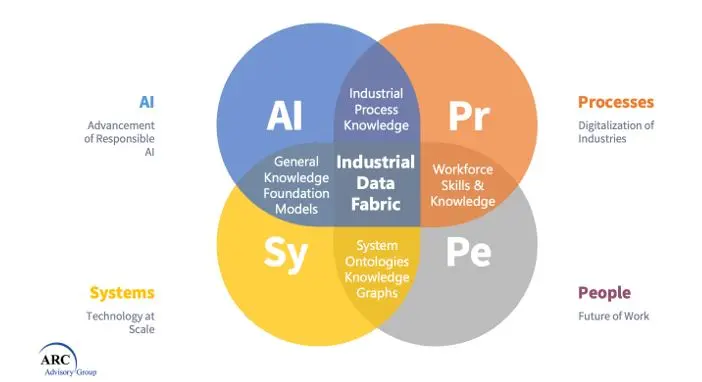
However one of the biggest barriers to escaping pilot purgatory and achieving sustainable business outcomes from scale deployment of these use cases at scale, is the need for a single version of the truth. It’s not that there’s not enough data, its being generated in abundance by connected devices, machines, processes, and people. Getting to a single version of the truth, and putting data into the right context for every stakeholder is why we put Industrial Data Fabric (IDF) at the center of ARC's Industrial AI Impact Assessment Model.
Industrial AI, a subset of the broader field of artificial intelligence, applies AI technologies in industrial settings to augment the workforce, enhance customer service, and drive growth, profitability, and sustainability. Techniques such as machine learning, deep learning, neural networks, and other AI approaches are used to build intelligent systems using data from various sources within an industrial environment.
For Industrial AI to be effective, it requires a robust and reliable data management system - a role fulfilled by Industrial Data Fabrics (IDFs). Serving diverse data needs of Information Technology (IT), Operational Technology (OT), Engineering Technology (ET), Business Analysts. Sustainability Champions and Data Science and AI audiences, and IDFs underpin the digitization and optimization of industrial operations.
There's no shortage of Data Fabrics from vendors as diverse as AWS, Databricks, IBM, Microsoft, Oracle, and Snowflake. However, the data fabrics that are used by industrial organizations to address factory and industrial AI use cases have different architectures and deployment options that suit their specific features and capabilities.
Industrial Data Fabrics weave together a unified, seamless layer for data management and integration across various endpoints, systems, and platforms within an industrial environment. This ecosystem encompasses diverse data sources like sensors, machinery, industrial engineers, and frontline workers, from within and beyond the organization.
Internal data, such as data from Enterprise Resource Planning (ERP) and Customer Relationship Management (CRM) systems, production lines, equipment, and employees, form the backbone of an organization's operations. This data provides valuable insights into the operational efficiency, productivity, and performance of different business units and processes. By facilitating the efficient management and integration of this internal data, IDFs allow organizations to optimize their operations, enhance productivity, reduce costs, and improve decision-making.
External data, on the other hand, comprises information from outside the organization, such as market trends, customer preferences, competitor information, regulatory changes, and environmental factors. This data is crucial for understanding the market dynamics, identifying opportunities and threats, anticipating customer needs, and staying competitive. Data may also be required from customers, design partners, logistics service providers, suppliers etc. Environmental, Sustainability and Governance (ESG) requires massive amounts of external data for Scope 2 and especially Scope 3 emissions calculations and reporting.
IDFs need to provide standardized solutions and methodologies to address common data management challenges, such as interoperability, scalability, real-time data processing, security, and governance. They facilitate end-to-end integration of data pipelines and cloud environments through intelligent and automated systems, while also allowing for flexibility and customization to cater to unique needs and legacy systems of different industrial organizations.
By enabling more detailed and expansive models of business activity, IDFs accelerate digital transformation and automation initiatives across industrial organizations. These models often begin as digital twins of equipment but later expand to represent entire manufacturing lines or even whole factories.
Industrial data is particularly challenging to manage in Data Fabrics (IDF) because of the following reasons:
Industrial data is diverse and complex: Industrial data can come from various sources and formats, such as sensors, machines, cameras, ERP systems, MES systems, SCADA systems, etc. Industrial data can also be structured, semi-structured, or unstructured, and contain different types of information, such as numerical, textual, image, video, audio, etc. Managing such diverse and complex data requires advanced techniques and tools to integrate, transform, analyze, and visualize the data .
Industrial data is dynamic and real-time: Industrial data is constantly generated and updated by production operations and processes. Factory data in particular needs to be processed and delivered with minimal latency or delay to support real-time decision making and action. Managing such dynamic and real-time data requires scalable and reliable architectures and platforms to handle the high velocity and veracity of the data .
Industrial data is sensitive and regulated: Industrial data can contain confidential and proprietary information about the factory products, processes, performance, customers, suppliers, etc. Industrial data can also be subject to various regulatory and industry standards and norms regarding data security, privacy, quality, compliance, etc. Managing such sensitive and regulated data requires appropriate policies, standards, controls, and technologies to safeguard data confidentiality, integrity, and availability .
Some examples of industrial data sources are:
Sensors are devices that measure physical quantities such as temperature, pressure, humidity, vibration, etc. and convert them into digital signals. Sensors can provide real-time and continuous data about the factory conditions, equipment status, product quality, etc.
Machines are devices that perform mechanical or electrical tasks such as cutting, drilling, welding, assembling, etc. Machines can provide data about the factory output, efficiency, utilization, maintenance, etc.
Cameras are devices that capture images or videos of the factory environment, processes, products, workers, etc. Cameras can provide data for computer vision applications such as object detection, recognition, tracking, etc.
ERP (Enterprise Resource Planning) systems are software applications that integrate and manage the core business processes of the factory such as finance, accounting, inventory, procurement, sales, etc. ERP systems can provide data about the factory resources, costs, revenues, orders, etc.
MES (Manufacturing Execution System) systems are software applications that monitor and control the factory production processes such as scheduling, dispatching, routing, tracking, etc. MES systems can provide data about the factory operations, performance, quality, etc.
SCADA (Supervisory Control and Data Acquisition) systems are software applications that collect and analyze data from sensors and machines and provide remote control and supervision of the factory equipment and processes. SCADA systems can provide data about the factory automation, safety, reliability, etc.
Real-time processing is the ability to process and deliver data with minimal latency or delay. Real-time processing requires implementing appropriate architectures, platforms, protocols, and techniques to enable timely and accurate data analysis and action across the IDF.
Data Virtualization. One approach to real-time processing in IDF is data virtualization. Data virtualization is a technique that creates a virtual data layer that integrates data from various sources without physically moving or copying the data. This allows users to leverage the source data in real-time, regardless of where it is stored or how it is formatted. Data virtualization also reduces the complexity and cost of data management, as well as the risk of data inconsistency and duplication. However data virtualization can create performance issues as it can put tremendous loads on production systems for complex queries, or the dependent data sources can create bottlenecks that create unacceptable latency for the destination systems.
Edge Computing. Another approach to meeting the real-time processing challenge in IDFs is edge computing. Edge computing is a paradigm that shifts some of the data processing from the cloud or central servers to the edge of the network, where the data is generated and consumed by devices such as sensors, cameras, or IoT devices. Edge computing can enable faster and more efficient decision making, especially for real-time applications that require low latency, high bandwidth, or high reliability. Edge computing can also enhance data security and privacy, as well as reduce network congestion and cloud dependency.
Stream Processing. A third approach to real-time processing in IDF is stream processing. Stream processing is a technique that processes data as it arrives in continuous streams, rather than in batches or at rest. Stream processing can enable real-time analytics, monitoring, and alerting on large volumes of data from various sources. Stream processing can also support complex event processing, which is the ability to detect and respond to patterns or anomalies in data streams.
These are some of the components and techniques that enable real-time processing in IDF. Real-time processing can provide many benefits for industrial organizations, such as improving operational efficiency, quality, safety, and customer satisfaction. However, real-time processing also poses some challenges, such as ensuring reliability and resilience of data systems, balancing speed with quality and cost, and integrating and synchronizing data from heterogeneous sources. Real-time processing in IDF requires careful planning, design, implementation, and evaluation to achieve optimal results.
Industrial Data Fabrics (IDF) are designed to handle various types of data and data management tools across different sources and environments. Some of the common types of data that IDF can integrate are:
Cloud data: Data that is stored and processed on cloud platforms, such as AWS, Azure, or Google Cloud. Cloud data can be accessed from anywhere and can scale up or down depending on the demand .
On-premises data: Data that is stored and processed on local servers or devices within an organization's network. On-premises data can offer more control and security but may require more maintenance and resources .
Data silos: Data that is isolated or disconnected from other data sources due to technical, organizational, or cultural barriers. Data silos can hinder data quality, consistency, and collaboration .
Data warehouses: Data that is structured, organized, and optimized for analytical purposes. Data warehouses can store historical and aggregated data from various sources and support complex queries and reports .
Data lakes: Data that is unstructured, raw, and diverse. Data lakes can store any kind of data from any source and support exploratory analysis and machine learning .
Edge data: Data that is generated and processed at the edge of the network, such as by sensors, cameras, or IoT devices. Edge data can enable faster and more efficient decision making, especially for real-time applications .
Time series data: Data that is collected and ordered by time, such as sensor readings, machine outputs, temperature measurements, sales records, etc. Time series data can enable monitoring, analysis, forecasting, optimization, and detection of trends, patterns, anomalies, etc.
BOM data: Data that lists the items, parts, components, subassemblies, and assemblies required for a product or a process. BOM data is essential for the product and its design, configuration, sales, manufacturing, maintenance, service, and retirement lifecycle.
ESG data: Data that reflects the environmental, social, and governance aspects of a company’s performance, such as its carbon emissions, diversity and inclusion, human rights, ethics, etc. ESG data is increasingly important for investors, regulators, customers, and other stakeholders who want to assess the sustainability and social impact of a company. ESG data can be divided into three scopes according to the GHG Protocol: Scope 1 emissions are the direct emissions from sources that are owned or controlled by the company; Scope 2 emissions are the indirect emissions from the generation of electricity, heat, or steam that the company purchases and consumes; Scope 3 emissions are the indirect emissions from the company’s value chain.
Some of the common data management tools that IDFs can leverage are:
Semantic knowledge graphs: Tools that use graph-based models to represent the meaning and relationships of data entities. Semantic knowledge graphs can enable intelligent integration, discovery, and inference of data across different domains and contexts .
Metadata management: Tools that use metadata (data about data) to describe the characteristics, quality, lineage, and usage of data assets. Metadata management can enable better governance, security, and compliance of data across the IDF .
Machine learning: Tools that use algorithms and models to learn from data and perform tasks such as classification, prediction, or recommendation. Machine learning can enable adaptive learning, detection, and optimization of data across the IDF .
Data catalogs: Tools that provide a searchable inventory of data assets and their metadata. Data catalogs can enable easier access, understanding, and collaboration of data across the IDF.
DataOps: Tools that apply agile and DevOps principles to data management processes. DataOps can enable faster, more reliable, and more collaborative delivery of data products across the IDF.
Business intelligence: Tools that provide visualizations, dashboards, and reports to analyze and communicate data insights. Business intelligence can enable better decision making and performance monitoring across the IDF.
We'll explore the capabilities of various commercial 'Data Fabrics' and their suitability for Industrial grade application development and Industrial AI use cases in future research.
Data integration and transformation: IDF can enable the seamless integration of data from various sources and formats, such as sensors, machines, ERP systems, MES systems, SCADA systems, etc. IDF can also enable the transformation of data into a common format and structure that can be used by knowledge graphs, vector database, different types of applications and analytics, and ESG reporting frameworks and standards. .
Data quality and validation: IDF can ensure the quality and reliability of the data by detecting and correcting errors, outliers, noise, missing values, etc. IDF can also validate the data against predefined rules and standards that apply to different types of applications and analytics.
Data security and privacy: IDF can protect the data from unauthorized access, use, modification, or destruction. IDF can also respect the privacy and consent of the data owners and subjects. IDF can implement appropriate policies standards controls technologies to safeguard data confidentiality integrity availability across the data lifecycle.
Data governance and ethics: IDF can adhere to ethical principles values when collecting processing sharing using data. IDF can also comply with relevant regulatory industry standards norms. IDF can implement appropriate frameworks methods tools practices to ensure that data is fair transparent accountable trustworthy human centric.
Data analytics and visualization: IDF can enable the efficient effective analysis of data using various techniques methods such as descriptive predictive prescriptive analytics machine learning artificial intelligence etc. IDF can also enable the clear concise communication of data insights using various techniques methods such as charts graphs dashboards reports etc.
Data scalability and elasticity: IDF can enable the scalability and elasticity of data storage and processing capabilities to meet the changing demands and requirements of the data. IDF can also leverage cloud computing and edge computing technologies to provide flexible and cost-effective solutions for data management.
Data innovation and collaboration: IDF can enable the innovation and collaboration of data across different stakeholders, such as business users, data engineers, data scientists, etc. IDF can also facilitate the creation and sharing of new data products or services that can generate value for the organization.
Foundation Models (FMs) are models that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. FMs have emerged as a powerful paradigm for developing and deploying Industrial AI applications, However, FMs also pose significant technical and ethical challenges, such as data quality, security, scalability, interpretability, fairness, and accountability.
To address these challenges, IDFs need to provide specific capabilities for building, extending, training, testing, and deploying (referred to as 'fine-tuning) FMs for Industrial AI use cases. Some of these capabilities are:
Model architecture and design: IDFs need to support the design and selection of suitable model architectures for FMs that can capture the complexity and diversity of the data and tasks. IDFs also need to support the customization and extension of FMs for specific domains and applications. IDFs should leverage state-of-the-art techniques such as transformers, attention mechanisms, graph neural networks, etc.
Model training and optimization: IDFs need to enable the efficient and effective training of FMs on large-scale and heterogeneous data. IDFs also need to optimize the performance and robustness of FMs for various metrics and objectives. IDFs should leverage state-of-the-art techniques such as distributed computing, parallelization, pruning, quantization, etc.
Model evaluation and validation: IDFs need to enable the rigorous and comprehensive evaluation of FMs on various dimensions such as accuracy, generalization, robustness, efficiency, etc. IDFs also need to validate the logic and outcomes of FMs for various scenarios and stakeholders. IDFs should leverage state-of-the-art techniques such as benchmarks, metrics, tests, explainability methods etc.
Model deployment and monitoring: IDFs need to enable the seamless and secure deployment of FMs on various platforms and environments such as cloud, edge, or hybrid. IDFs also need to monitor the performance and impacts of FMs in real-time or near real-time. IDFs should leverage state-of-the-art techniques such as containers orchestration tools, feedback loops, alerts etc.
The integration of Industrial AI into modern software design patterns puts an even greater spotlight on the capabilities and benefits of Industrial Data Fabrics. By providing a robust and reliable data management system, IDFs can play a crucial role in the industrial AI (R)evolution, enabling organizations to achieve their digital transformation and sustainability goals with modern software design patterns that accelerate the development of cloud-to-edge, industrial AI enhanced solutions.
For more information or to contribute to Industrial AI and Industrial Data Fabrics research, please contact Colin Masson at cmasson@arcweb.com .